The pipeline layer for Apache Iceberg
Iceberg defines table state and evolution. Etleap provides the pipeline layer that keeps those tables fed, coordinated, and correct in production.
Why Iceberg is a strong data foundation
Iceberg is increasingly used as a foundation for modern data architectures. Its consistent table semantics, shared access model, and support for safe evolution make it well suited for long-lived data systems powering analytics, data products, and AI.
Open and vendor-neutral
Built on open standards, Iceberg is not tied to a single engine, cloud, or vendor.
Shared data access
Multiple engines can read and write the same tables without copying or syncing data.
Schema and table evolution
Schemas and partitions can evolve safely over time without breaking existing data products.
Consistent table semantics
The same table behavior and guarantees apply across all supported query engines.

What Iceberg doesn’t handle
Iceberg defines how tables are stored and how they evolve. It does not manage ingestion, coordinate transformations, or operate tables over time. Those responsibilities belong to a pipeline layer that keeps Iceberg tables up to date and reliable in production.
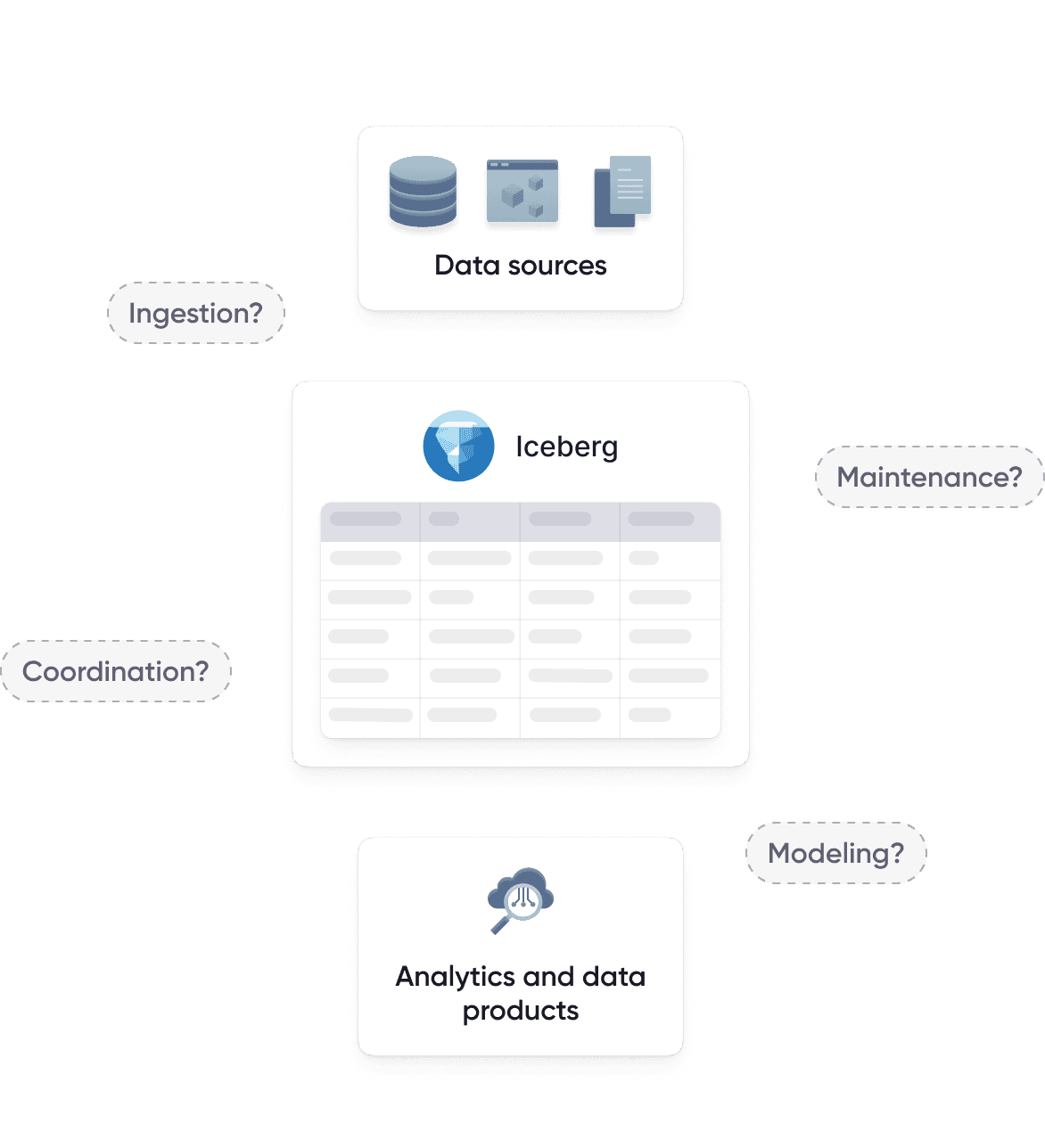
The pipeline layer around Iceberg
A pipeline layer turns Iceberg from a table format into a running data system. It provides the continuous flow of data, synchronization with transformations, and automated upkeep that makes Iceberg usable day to day.
Etleap provides this pipeline layer around Iceberg. It makes the operational loop continuous and dependable, so teams can rely on Iceberg as a single data foundation rather than a collection of disconnected jobs.











