What is a Data Lakehouse?
A data lakehouse merges the best of data lakes and warehouses, adding a processing layer to enable direct querying of data in lakes (like S3) without needing to load it into a warehouse first.

A data lakehouse combines the best elements of data lakes and data warehouses into a single data storage solution. By adding a processing layer on top of data lakes (like S3), data lakehouses enable you to directly query the data in your data lakes without needing to load it into a data warehouse first.
Data warehouses are most commonly used for business intelligence purposes, whereas data lakes are used for analytical workloads and data science.
There are advantages and disadvantages associated with each storage solution.
A data warehouse is not considered the most effective data store for unstructured data, semi-structured data, or data from multiple sources. All of which are becoming more common in business intelligence.
In comparison, data lakes can store raw data in a variety of formats. However, they lack some critical features. They do not support ACID transactions, lacking consistency and making it difficult to mix batch and streaming jobs. Which in turn, makes it difficult to query and combine data.
Because of this, most organizations today use a combination of data lakes and data warehouses to manage and store their data. It is common to have a data warehouse (or multiple warehouses) working in parallel with a data lake.
While combining data lakes and data warehouses in your architecture theoretically reaps the benefits of both, in reality, it causes undue complexity and lack of consistency. Data that is moved or copied between different systems causes delays and jeopardizes data integrity.
To counter this problem, some organizations have started to embed their data warehouses in their data lake endeavoring to create a single data storage solution.
Similarly, a data lakehouse builds upon this idea. A data lakehouse is a single platform that can be used to house data for business intelligence purposes, as well as data science and analytical workloads.
Directly connect to BI tools
Data lakehouses support direct connection to popular BI tools such as Tableau and Power BI. These BI tools can directly access the source data, reducing the time from raw data to visualization.
Support for diverse data types and workloads
Lakehouses can store unstructured and semi-structured data, including data from both batched and streaming jobs. They also enable diverse workloads including SQL, analytics, machine learning, and data science.
Reduced data redundancy
By combining elements of data warehouses and data lakes, lakehouses reduce data redundancy. They eliminate the need to store data across multiple systems, allowing you to use a single system to store, refine and analyze raw data. Which in turn, allows organizations to establish a single source of truth with their data.
Transaction support
In larger organizations, different teams are often working with various data pipelines concurrently. Data lakehouses support ACID transactions, ensuring consistency as multiple data pipelines read and write data.
Simplified schema and data governance
When working with sensitive data, there are additional steps for managing governance when transferring data from one tool to another. Managing security and access across multiple data stores is often time-consuming and error-prone.
Data lakehouses provide a single point of control for managing data governance and access control.
Lakehouses are also able to support schema enforcement, simplifying schema management. They support data warehouse design patterns such as star or snowflake schemas.
The goal of a data lakehouse is to combine the best elements of a data warehouse and data lake. A lakehouse is a cost-effective storage solution of data lakes, with improved data reliability and structure.
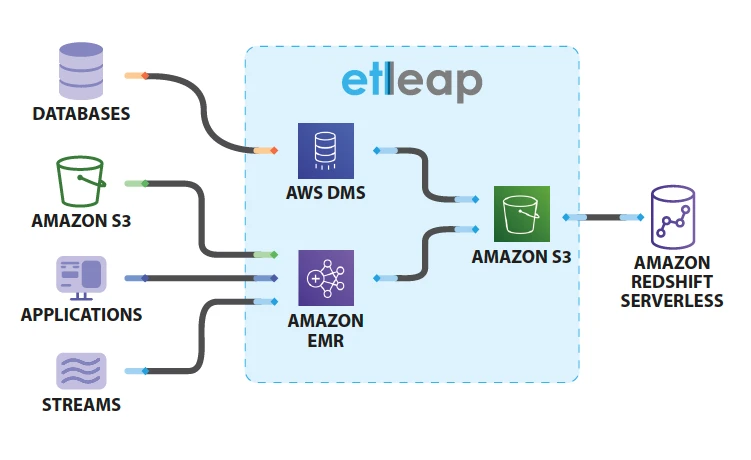
Since lakehouses work by layering processing power on top of data lakes, an ETL pipeline is required between the data lake layer and the integrated warehouse layer.
To reap the benefits of data lakehouses, you need to be able to integrate and transform data from various data sources across various data types. Etleap is built to integrate all of your sources and manage unstructured and semi-structured data.
Automating the data flows and transformations across these data types allows data science teams to create easily repeatable workflows, saving valuable engineering time.