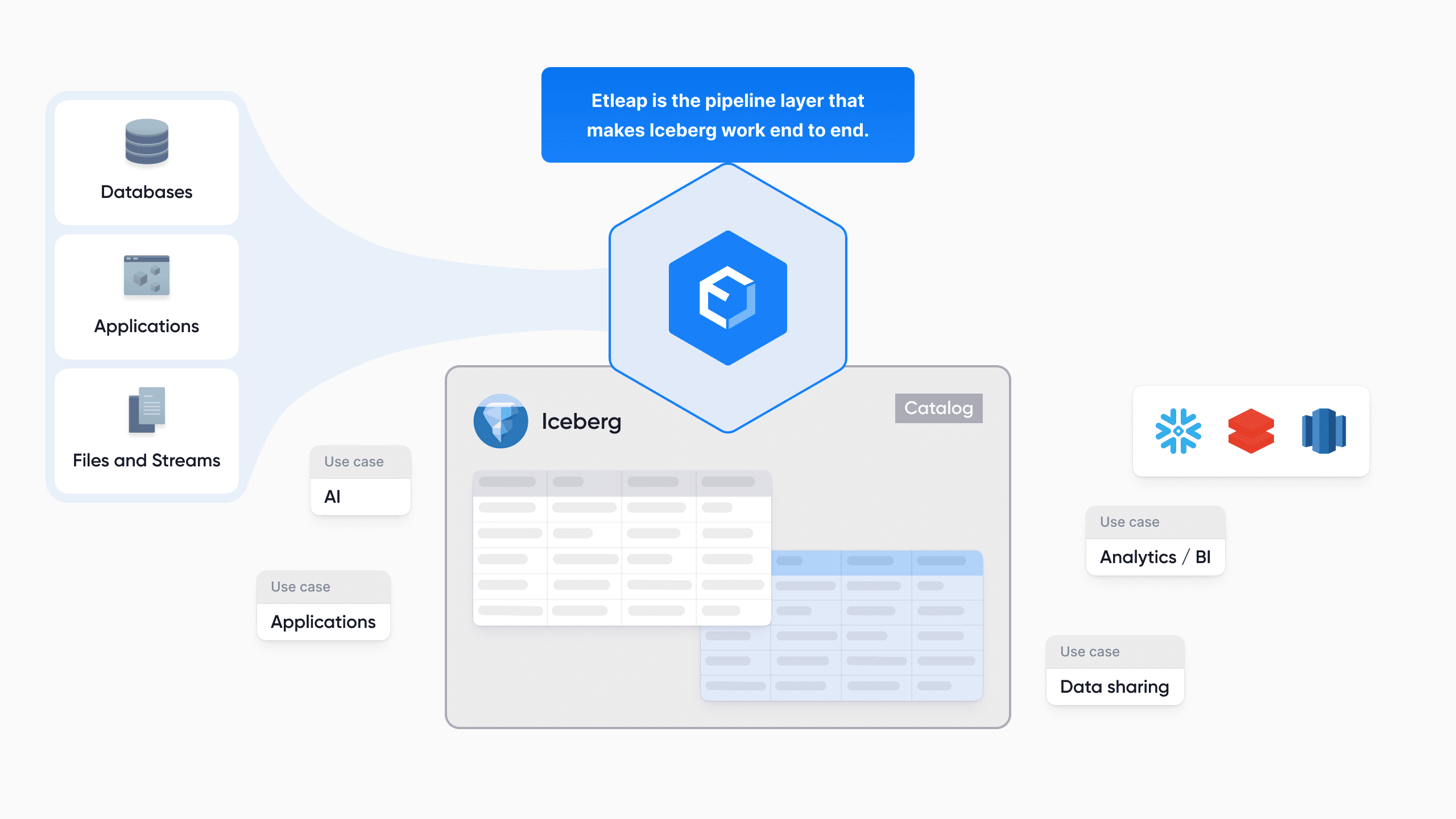
Streaming fresh data into Apache Iceberg is straightforward until you have to apply updates. Iceberg gives you two ways to delete rows, and they pull in opposite directions: equality deletes are cheap to write but expensive to query, while position deletes are the other way around. Streaming engines like Apache Flink lean on equality deletes to keep write latency low, which leaves you with tables that are slow to read, and that engines like Snowflake and Databricks can't read at all.
The talk below walks through a practical way out. Etleap ingests with fast equality deletes, then converts them to position deletes (deletion vectors) on a separate Iceberg branch in the background, copying data files instead of rewriting them. The payoff: fast writes and fast reads on the same table, at sub-minute freshness even across hundreds of millions of rows.
In this session we cover the design and implementation of this process in depth, and show how easy it is to set up a pipeline that uses this mechanism in Etleap, and take a look at it in action on a large dataset.
The problem: updating Iceberg tables from a stream
However, efficiently applying updates to Iceberg tables from streamed data is still an unsolved problem. Iceberg supports row-level updates through deletion marker files: position-based deletes (position deletes and deletion vectors (DVs)) and equality deletes. Position-based deletes identify deleted versions of rows by their physical location in the table, and equality deletes identify records by values of fields in the data. The choice between these two types of deletes offers a trade-off between write latency and query performance: equality deletes are fast to write but slow to query, and position deletes require a point lookup for each record but are much more efficient at read-time. Furthermore, many mainstream readers like Snowflake and Databricks don’t support equality deletes at all, meaning that writing updates from streaming frameworks such as Apache Flink will result in tables that you can’t query from your warehouse.
In this technical deep-dive session, we cover some common workarounds like changelog tables, MERGE INTO materialization, and aggressive compaction. These handle streams and produce tables that work anywhere, but also result in high end-to-end latency, high write amplification as data needs to be rewritten, and a higher operation overhead that make them unsuitable for customer’s needs.
How Etleap solves it
At Etleap, we have developed a process that uses branching to ingest streaming data directly to Iceberg with low-latency using equality deletes, and converts the equality delete files to deletion vectors which are written to a separate branch. Data files are simply copied from one branch to the other, so no data needs to be written more than once. Only the branch that contains DVs is exposed downstream, so queries are performant, make full-use of native Iceberg features and, importantly, work anywhere.
The conversion process is implemented as a continuous streaming job which makes use of Iceberg’s natural metadata structure to efficiently detect changes to the table and read and rewrite only the files that need conversion. This results in an end-to-end latency of under 1 minute, even on large tables with 500 million records. This process is used by Etleap pipelines automatically, and works out-of-the-box to provide a good trade-off between end-to-end latency and performant Iceberg tables.
There are some key challenges to solve to ensure this works reliably. Iceberg table maintenance such as file compactions pose a significant problem for position-based deletes in that the two naturally conflict. The conversion approach presented in this session was designed with this in mind. We cover how branching enables both compactions and position-based deletes to run side-by-side without conflicts, and without needing to interrupt the flow of data or schedule the two jobs around each other.
Setting it up in Etleap
The result is a pipeline our customers can set up in just a few clicks through the Etleap dashboard. Flink handles ingestion and transformation, the conversion process runs continuously in the background, and the final Iceberg table is fully readable in Snowflake, Databricks, or whichever query engine your team relies on with sub-minute end-to-end latency. For teams that need real-time Iceberg updates without sacrificing compatibility or query performance, this architecture delivers all of this together in a way that is practical to run in production today.