This blog post was written in partnership with the Amazon Redshift team, and also posted on the AWS Big Data Blog.
The materialized views feature in Amazon Redshift is now generally available and has been benefiting customers and partners in preview since December 2019. One customer, AXS, is a leading ticketing, data, and marketing solutions provider for live entertainment venues in the US, UK, Europe, and Japan. Etleap, an Amazon Redshift partner, is an extract, transform, load, and transform (ETLT) service built for AWS. AXS uses Etleap to ingest data into Amazon Redshift from a variety of sources, including file servers, Amazon S3, relational databases, and applications. These ingestion pipelines parse, structure, and load data into Amazon Redshift tables with appropriate column types and sort and distribution keys.
Improving dashboard performance with Etleap models
To analyze data, AXS typically runs queries against large tables that originate from multiple sources. One of the ways that AXS uses Amazon Redshift is to power interactive dashboards. To achieve fast dashboard load times, AXS pre-computes partial answers to the queries dashboards use. These partial answers are orders of magnitude smaller in terms of the number of rows than the tables on which they are based. Dashboards can load much faster than they would if they were querying the base tables directly by querying Amazon Redshift tables that hold the pre-computed partial answers.
Etleap supports creating and managing such pre-computations through a feature called models. A model consists of a SELECT query and triggers for when it should be updated. An example of a trigger is a change to a base table, that is, a table the SELECT statement uses that defines the model. This way, the model can remain consistent with its base tables.
The following screenshot shows an Etleap model with two base table dependencies.
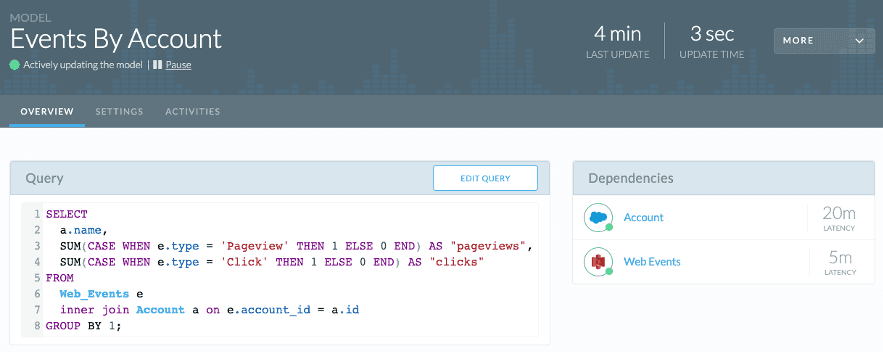
Etleap represents their models as tables in Amazon Redshift. To create the model table, Etleap wraps the SELECT statement in a CREATE TABLE AS (CTAS) query. When an update is triggered, for example, due to base table inserts, updates, or deletes, Etleap recomputes the model table through the following code:
CREATE TABLE model_temporary AS SELECT …
DROP TABLE model;
RENAME TABLE model_temporary TO model;
Analyzing CTAS performance as data grows
AXS manages a large number of Etleap models. For one particular model, the CTAS query takes over 6 minutes, on average. This query performs an aggregation on a join of three different tables, including an event table that is constantly ingesting new data and contains over a billion rows. The following graph shows that the CTAS query time increases as the event table increases in number of rows.
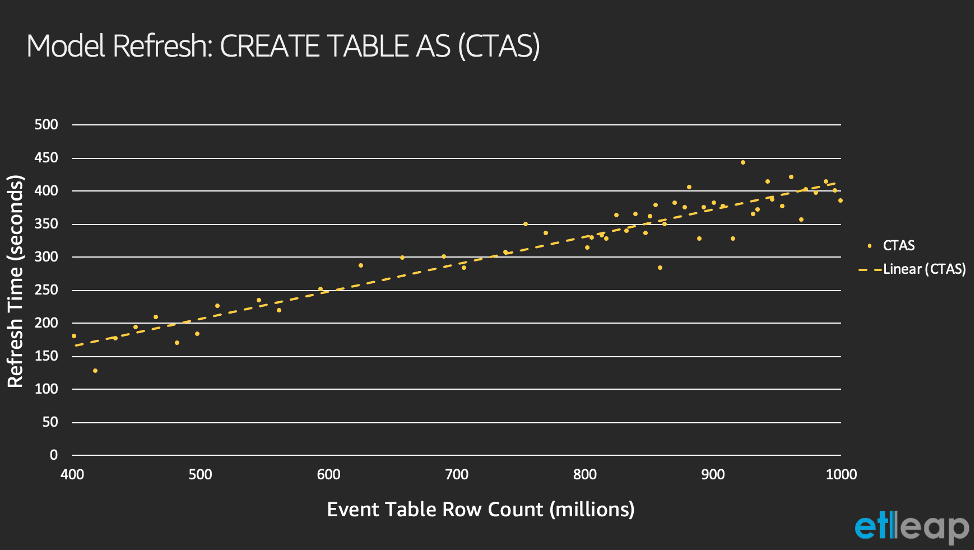
There are two key problems with the query taking longer:
There’s a longer delay before the updated model is available to analysts
The model update consumes more Amazon Redshift cluster resources
To address this, AXS would have to resort to workarounds that are either inconvenient or costly, such as archiving older data from the event table or expanding the Amazon Redshift cluster to increase available resources.
Comparing CTAS to materialized views
Etleap decided to run an experiment to verify that Amazon Redshift’s materialized views feature is an improvement over the CTAS approach for this AXS model. First, they built the materialized view by wrapping the SELECT statement in a CREATE MATERIALIZED VIEW AS query. For updates, instead of recreating the materialized view every time that data in a base table changes, a REFRESH MATERIALIZED VIEW query is sufficient. The expectation was that using materialized views would be significantly faster than the CTAS-based procedure. The following graph compares query times of CTAS to materialized view refresh.
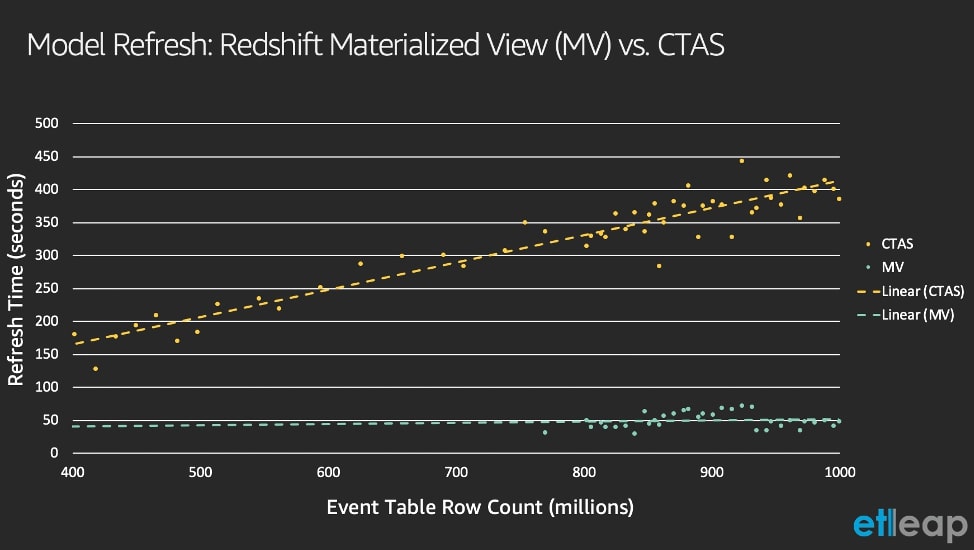
Running REFRESH MATERIALIZED VIEW was 7.9 times faster than the CTAS approach—it took 49 seconds instead of 371 seconds on average at the current scale. Additionally, the update time was roughly proportional to the number of rows that were added to the base table since the last update, rather than the total size of the base table. In this use case, this number is 3.8 million, which corresponds to the approximate number of events ingested per day.
This is great news. The solution solves the previous problems because the delay the model update caused stays constant as new data comes in, and so do the resources that Amazon Redshift consume (assuming the growth of the base table is constant). In other words, using materialized views eliminates the need for workarounds, such as archiving or cluster expansion, as the dataset grows. It also simplifies the refresh procedure for model updates by reducing the number of SQL statements from three (CREATE, DROP, and RENAME) to one (REFRESH).
Achieving fast refresh performance with materialized views
Amazon Redshift can refresh a materialized view efficiently and incrementally. It keeps track of the last transaction in the base tables up to which the materialized view was previously refreshed. During subsequent refreshes, Amazon Redshift processes only the newly inserted, updated, or deleted tuples in the base tables, referred to as a delta, to bring the materialized view up-to-date with its base tables. In other words, Amazon Redshift can incrementally maintain the materialized view by reading only base table deltas, which leads to faster refresh times.
For AXS, Amazon Redshift analyzed their materialized view definitions, which join multiple tables, filters, and aggregates, to figure out how to incrementally maintain their specific materialized view. Each time AXS refreshes the materialized view, Amazon Redshift quickly determines if a refresh is needed, and if so, incrementally maintains the materialized view. As records are ingested into the base table, the materialized view refresh times shown are much faster and grow very slowly because each refresh reads a delta that is small and roughly the same size as the other deltas. In comparison, the refresh times using CTAS are much slower because each refresh reads all the base tables. Moreover, the refresh times using CTAS grow much faster because the amount of data that each refresh reads grows with the ingest rate.
You are in full control of when to refresh your materialized views. For example, AXS refreshes their materialized views based on triggers defined in Etleap. As a result, transactions that are run on base tables do not incur additional cost to maintain dependent materialized views. Decoupling the base tables’ updates from the materialized view’s refresh gives AXS an easy way to insulate their dashboard users and offers them a well-defined snapshot to query, while ingesting new data into base tables. When AXS vets the next batch of base table data via their ETL pipelines, they can refresh their materialized views to offer the next snapshot of dashboard results.
In addition to efficiently maintaining their materialized views, AXS also benefits from the simplicity of Amazon Redshift storing each materialized view as a plain table. Queries on the materialized view perform with the same world-class speed that Amazon Redshift runs any query. You can organize a materialized view like other tables, which means that you can exploit distribution key and sort columns to further improve query performance. Finally, when you need to process many queries at peak times, Amazon Redshift’s concurrency scaling kicks in automatically to elastically scale query processing capacity.
Conclusion
Now that the materialized views feature is generally available, Etleap gives you the option of using materialized views rather than tables when creating models. You can use models more actively as part of your ETLT strategies, and also choose more frequent update schedules for your models, due to the performance benefits of incremental refreshes
For more information about Amazon Redshift materialized views, see Materialize your Amazon Redshift Views to Speed Up Query Execution and Creating Materialized Views in Amazon Redshift.
by Christian Romming, Prasad Varakur (AWS), and Vuk Ercegovac (AWS)







