New feature: End-to-end Pipelines with dbt Core
Etleap now supports end-to-end pipelines with dbt Core, streamlining data workflows and enhancing analytics stack!
Today, I’m excited to share that Etleap is launching support for end-to-end pipelines with dbt Core! Our product team has been working on this feature, which we call dbt Schedules, for several months, our awesome users have been providing invaluable feedback on early designs, and waited patiently to try it out. I can’t wait to see how our users incorporate dbt Schedules into their analytics stacks!
I think of this as a big step in the direction of self-serve data pipelines, and I’d like to take this opportunity to reflect on how we got here, and how I think dbt Schedules fits into the workflow of today’s modern data teams.
I started Etleap because I was frustrated with the amount of engineering effort required to build robust and scalable data pipelines. As an engineering and analytics leader at my previous company I saw first-hand how much friction there was in creating and managing internal and external data products - both for the developers and the analysts. So much back-and-forth between people and roles getting data samples, coding ingestion pipelines, iterating on SQL queries, making everything performant, etc. It was exhausting! At the time, we were actually dabbling with the idea of self-serve ELT for analysts, but this was before LookML and dbt Core, and we got discouraged by how daunting it seemed to create the tooling to make self-serve ELT a reality.
At Etleap, we started at the other end of the data pipeline: data ingestion. We built support for structured (databases, applications) and semi-structured (files, events) data sources to enable developers and analysts to create ingestion pipelines in minutes. Rapid improvements in data ingestion allowed data teams to centralize all their data with minimal effort while maintaining a high degree of control over pipeline operations.
With improvements come new challenges. Our users then told us they wanted to do more with the data once ingested into their warehouse. So a few years ago, we added the ability to create SQL models with dependency management in Etleap. This feature enables users to operationalize their SQL models by triggering automatic updates when source data changes, letting them stay on top of issues with their models, such as incompatible schema changes.
Some of our users have added hundreds of these models on top of their data pipelines. This is strong evidence that dependency management between ingestion pipelines and SQL models is a useful construct for data teams. However, there were a couple of signs that our initial approach to models was bursting at the seams at this scale. First, with independent scheduling and dependency management for each model, it becomes hard to reason about how up-to-date the model data is - in particular when there are multiple levels of dependencies. Second, as users’ models become more numerous and complex, the lack of SQL code collaboration features and version control becomes a productivity blocker.
We had ideas for how to build features to address these challenges into Etleap. However, at the same time as models were gaining popularity among Etleap users, so was another tool for SQL modeling in the wider data community: dbt Core. It grew quickly as an open-source project, and we saw many of our customers using it successfully with Etleap data. After exploring this technology, we decided there is enough overlap between the functionality and philosophy of dbt Core and Etleap models to warrant fully adopting dbt Core in our product.
Collaboration and version control are at the foundation of dbt Core. Teams can check in their dbt Core models to their Git repositories, collaborate through pull request reviews, and have dbt model documentation created automatically.
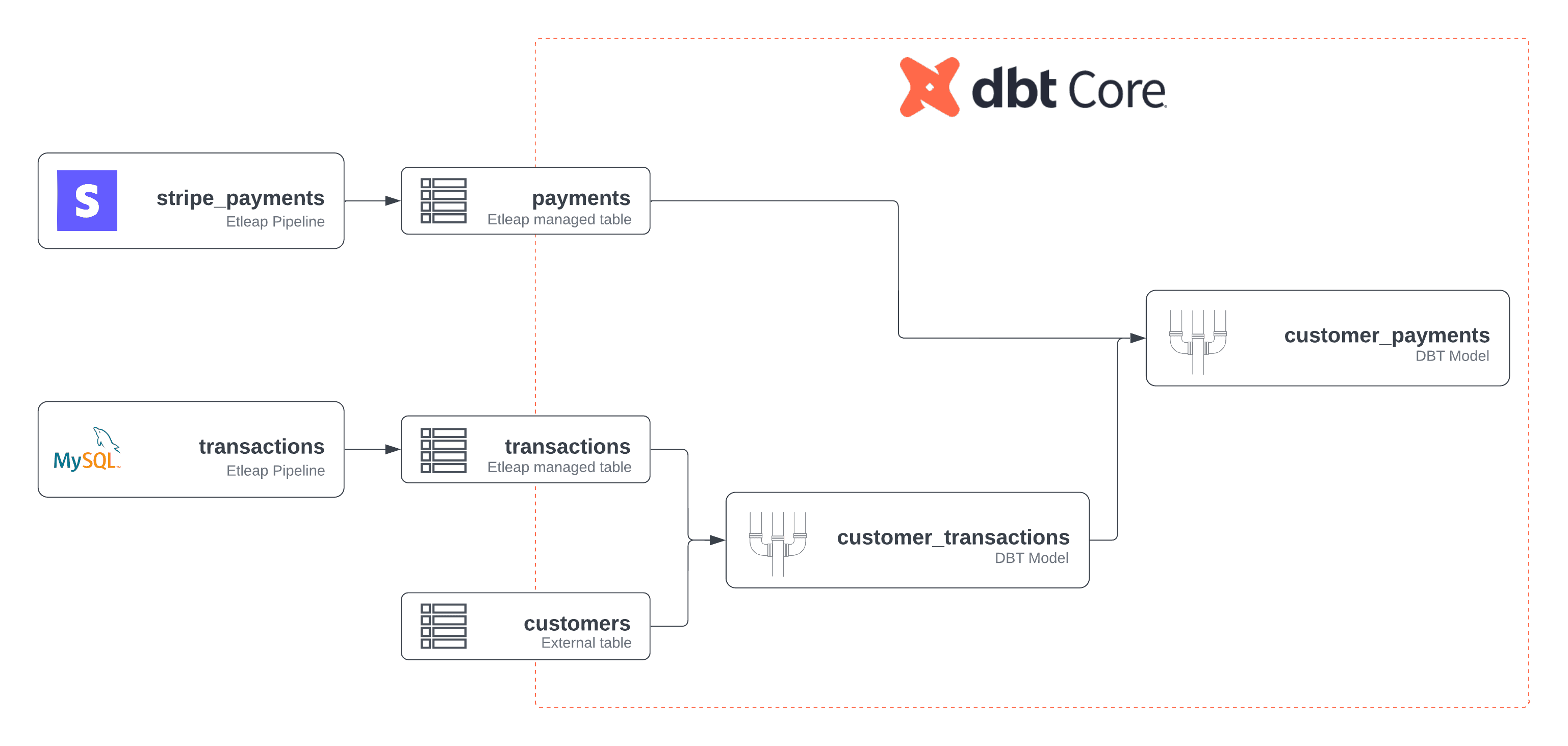
We think these dbt Core features will be even more powerful when used together with Etleap ingestion in end-to-end pipelines. The coupling of ingestion pipelines and SQL models was a core idea of Etleap models, and dbt Schedules are based on this concept as well. Etleap automatically matches up dbt sources with Etleap ingestion pipelines, so that users get a seamless integration of the two.
Another key end-to-end pipeline feature is scheduling. Etleap users that also used dbt Core previously would have to use a separate scheduling tool for their dbt Core builds. With dbt Schedules, users can let Etleap trigger dbt Core builds. Since ingestion pipelines can also be included in the schedule, users can now ensure that Etleap dependencies in their models are guaranteed fresh, and reason about the models’ freshness back to the upstream sources, such as databases and application pipelines.
Getting started with ETLT pipelines in Etleap is straightforward: hook up your GitHub repo where your dbt Core models live, pick the selector you want to schedule, along with the cron expression for your schedule, and Etleap handles the rest.
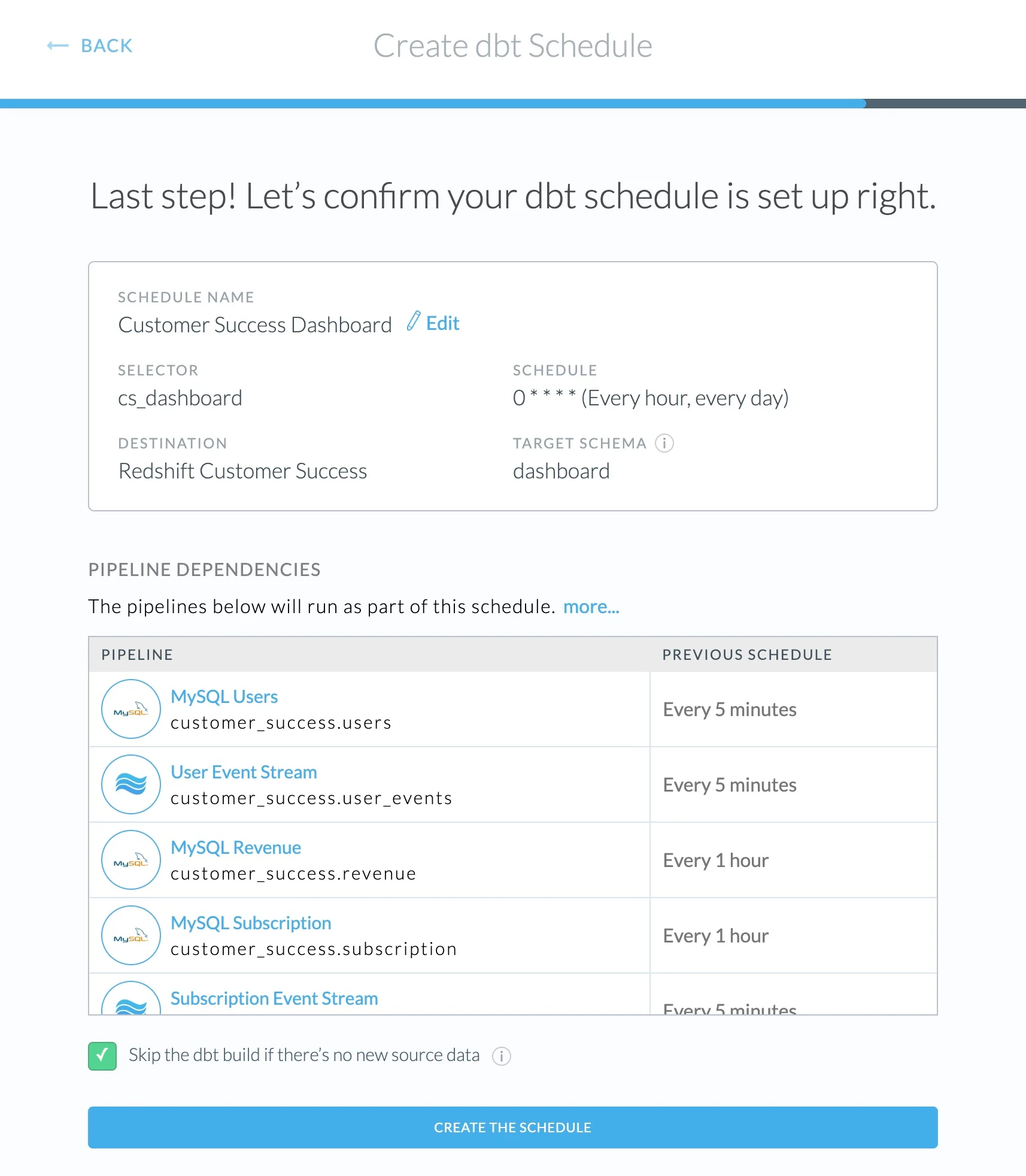
To configure a dbt Schedule in Etleap, specify a dbt selector and a cron expression. Etleap automatically matches dbt sources to Etleap ingestion pipelines to make them part of the end-to-end schedule.
I believe this is a significant step in the direction of making data pipelines self-serve for data consumers. At my former company, using this approach would let our analysts and scientists be self-sufficient in creating internal or external data products, instead of relying on the engineering team to do the heavy lifting for them. Here is how a high-level workflow could go for the data workers using Etleap dbt Schedules:
Identify the data sources, such as file stores, databases, and applications, and connect to them in Etleap.
Create ingestion pipelines by selecting source objects and interactively wrangling the data into shape, if necessary. Etleap creates tables in their data warehouse and keeps them up to date with new data.
In a SQL editor, query the ingested data to explore and derive models.
Add the models to the version-controlled dbt repository, and replace table mentions with dbt source references. Add dbt tests to ensure high data quality.
Raise a pull request and iterate with the applicable team. Define a selector for the set of models to build together.
Schedule the selector in Etleap. The models are now in production.
Refine and evolve the models as data needs evolve through further pull requests.
The neat thing about these 7 steps is they can be completed by anyone who knows SQL, giving those users access to data pipeline features that have traditionally been available only to highly skilled data engineers, including the ability to guarantee and reason about data freshness and pipeline stability.
The whole team at Etleap is excited to hear the feedback we get from our users, and we’ll strive to make these end-to-end pipelines more and more usable in the weeks and months ahead.
If you’d like to try this yourself, contact us here or start an Etleap trial from your Snowflake and Redshift dashboards.